文章出處

學了這么些天的基礎知識發現自己還是個門外汗,難怪自己一直混的不怎么樣。但這樣的惡補不知道有沒有用,是不是過段時間這些知識又忘了呢?這些知識平時的工作好像都是隨拿隨用的,也并不是平時一點沒有關注過這些基礎知識,只是用完了也就忘了。所以寫筆記也是個好習慣,光看一個概念不容易記住,整理寫成文那就好許多,以后查起來也方便一些。
為什么要用Hash Table?
這就想到了以前工作中遇到的一個事情。多年前我還在寫delphi,軟件功能中有許多的批量數據運算,由于數據要拉取到內存中,然后多個數據集合間進行遍歷查找對比,這樣的話數據量一多就會非常的慢,而且經常會遇到內存錯誤,一直也找不出原因。后來有一位經驗豐富的老程序員加入,他就提出了使用hashtable來解決這個問題。
經過測試果然大幅度的提高了性能,以下就來簡單分析下:
我們的數據對象是通過對比主鍵字段進行定位的,而這個字段是string類型,長度為40,要在一個數據集合中找一條數據就要去遍歷,然后對比主鍵是否相同,這就有兩個問題:
1、字符串與字符串進行比較如果量少問題不大,如果數據量大的話就是個很大的問題,畢竟每次都是40個字節與40字節長度對比呀
2、由于數據是存在內存鏈表中的,想要定位一個數據就要搜索查找,更何況是大量的循環查找
要解決這兩個問題分別要做什么:
1、減少主鍵字段對比時的時間,比如采用整形類型,這樣就只有4個字節
2、優化算法,提高數據查找效率,或者提高數據定位的效率
我們采用的hashtable很符合這些要求,Hashtable的存儲結構使用的是:數組+鏈表的方式。
首先,將數據存在數組中,利用數組的尋址能力不就很快嗎
其次,對Key進行hash運算,這樣就可以使用Int類型,這又解決了字符串比較的問題
看到了好處就有了繼續學習下去的動力了,一步步來吧。
什么是Hash Table
對于Hash table名字應該不陌生,先看看定義吧
散列表(Hash table,也叫哈希表),是根據關鍵字(Key value)而直接訪問在內存存儲位置的數據結構。也就是說,它通過把鍵值通過一個函數的計算,映射到表中一個位置來訪問記錄,這加快了查找速度。這個映射函數稱做散列函數,存放記錄的數組稱做散列表。
要理解的具體一點,就要將散列這個概念多了解一些,還是繼續看維基百科吧,一點點來理解:
- 若關鍵字為
,則其值存放在
的存儲位置上。由此,不需比較便可直接取得所查記錄。稱這個對應關系
為散列函數,按這個思想建立的表為散列表。
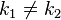 ,而
,而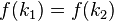 ,這種現象稱為碰撞(
,這種現象稱為碰撞(這里說了幾個比較重要的概念:關鍵字、散列函數、碰撞。應該說已經說的很明白了,沒啥好難理解的。
散列函數有許多種實現方法,下面也列一下吧:
散列函數能使對一個數據序列的訪問過程更加迅速有效,通過散列函數,數據元素將被更快定位。
- 直接定址法:取關鍵字或關鍵字的某個線性函數值為散列地址。即
或
,其中
為常數(這種散列函數叫做自身函數)
- 數字分析法:假設關鍵字是以r為基的數,并且哈希表中可能出現的關鍵字都是事先知道的,則可取關鍵字的若干數位組成哈希地址。
- 平方取中法:取關鍵字平方后的中間幾位為哈希地址。通常在選定哈希函數時不一定能知道關鍵字的全部情況,取其中的哪幾位也不一定合適,而一個數平方后的中間幾位數和數的每一位都相關,由此使隨機分布的關鍵字得到的哈希地址也是隨機的。取的位數由表長決定。
- 折疊法:將關鍵字分割成位數相同的幾部分(最后一部分的位數可以不同),然后取這幾部分的疊加和(舍去進位)作為哈希地址。
- 隨機數法:將關鍵字分割成位數相同的幾部分,最后一部分位數可以不同,然后取這幾部分的疊加和(去除進位)作為散列地址。數位疊加可以有移位疊加和間界疊加兩種方法。移位疊加是將分割后的每一部分的最低位對齊,然后相加;間界疊加是從一端向另一端沿分割界來回折疊,然后對齊相加。
- 除留余數法:取關鍵字被某個不大于散列表表長m的數p除后所得的余數為散列地址。即
,
。不僅可以對關鍵字直接取模,也可在折疊法、平方取中法等運算之后取模。對p的選擇很重要,一般取素數或m,若p選擇不好,容易產生碰撞。
有點懸乎,無非就是直接用某個數字或者通過計算得到一個數字作為數組的下標,就是存儲的位置地址,這樣存與取都可以直接定位了,簡單高效。不管是哪一種方法都有一個共同的問題,就是hash計算結果可能相同,也就是碰撞問題。那么就得有辦法去解決這問題,看了看資料有幾種方法:
- 開放定址法:如果發生沖突就繼續找下一個空的散列地址
- 單獨鏈表法:即在發生沖突的位置直接使用鏈表保存沖突的數據
- 再散列:即在上次散列計算發生碰撞時,用另一個散列函數計算新的散列函數地址,直到碰撞不再發生
- 建立公共溢出區:建立基本表和溢出表,沖突的就放到溢出區
參考文章:
http://zh.wikipedia.org/zh/%E5%93%88%E5%B8%8C%E8%A1%A8
http://c.biancheng.net/cpp/html/1031.html
簡單學習下Hash Table的機制
到這好像也差不多了解了HashTable的作用與好處,接下來就有了繼續學習HashTable的動力。前面提到的那個Delphi的Hash Table類使用的存儲結構是數組+鏈表的形式,源代碼也找不到了,下面就以Java的Hash Table類作為對象來學習吧。
-
存儲結構
對于Java SDK中默認實現的HashTable類使用的存儲結構是數組+單鏈表,有了前面的概念就明白了,數組即是用于存儲數據的連續的地址空間,而鏈表是用來解決碰撞問題的。這樣就利用了數組高效的尋址能力,又通過鏈表解決了碰撞的存儲問題。
先看數組:
/** * The hash table data. */ private transient Entry[] table;
再看數據鏈表
/** * Hashtable collision list. */ private static class Entry<K,V> implements Map.Entry<K,V> { int hash; K key; V value; Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } protected Object clone() { return new Entry<K,V>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } // Map.Entry Ops public K getKey() { return key; } public V getValue() { return value; } public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ (value==null ? 0 : value.hashCode()); } public String toString() { return key.toString()+"="+value.toString(); } }
其實還是挺簡單的,就是一個Entry數組,而Entry就是一個鍵值關系表,同時提供了鏈表的功能。
-
數據存取
寫了這么多代碼,打開Hashtable的代碼發現也就這那些東西吧,關鍵的是就是存與取。
先看存一個數據的方法put:
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<K,V>(hash, key, value, e); count++; return null; }
- 這里看到了線程同步關鍵字,因為整個hashtable都是線程同步的,所以在線程里用也是木有問題的
- 注意valua是不能為null的會拋異常
- 將要存的數據以key-value的方式放進去,先通過key計算Hash值,就是數組位置
看看關鍵代碼:
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
先得到key的hashcode,再通過除留余數法得到數組索引,簡單高效就得到了存儲位置。
- 然后后面的代碼看看有沒有相同的項目,有則替換之。最后創建一個Entry對象保存數據,如果存在碰撞Entry會自動寫入鏈表中解決沖突。
獲得數據的方法就是get:
public synchronized V get(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
計算數組下標的方法是一樣的,這樣的定位方式特別高效,只要計算一次就可以了,當然如果有沖突的話還要遍歷鏈表對比hash和key再確定最終的數據項。
再看看HashMap
在haspMap中實現的思想其實和hashtable大體相同,存儲結構也類似,只是一些小區別:
- key和value支持null,這種情況下總是存在數組中的第一個元素中,感覺是種特殊公共溢出區的應用
- 不是線程安全的,需要自己做線程同步
- 計算存儲位置時采用了在hashcode上再次hash+indexFor的方法,使得得到的散列值更均勻
| 不含病毒。www.avast.com |
全站熱搜

 留言列表
留言列表
